When 20 AI Agents Becomes a Problem (และจะแก้ยังไงดี)


English version published here: https://www.arcfusion.ai/blog/when-20-ai-agents-becomes-a-problem
CFO ถามว่า AI spend ปีนี้ขึ้น 4 เท่า แล้วอยากรู้ว่าถ้าแบ่งดูแต่ละ business unit เป็นยังไง Engineering บอกได้แค่ยอดรวม เพราะแต่ละทีม tag usage ต่างกัน สุดท้ายได้ spreadsheet ที่ dev นั่งทำข้อมูลเอง แล้วก็พังอีกทีตอนมี agent ใหม่ ship ออกมาโดยไม่มี tag เลย
CIO เจอปัญหาอีกแบบ – Q&A bot ภายใน ดึง document ที่มีข้อมูลลับออกมาให้ user ที่ไม่ควรเห็น ที่น่ากลัวไม่ใช่แค่ bot ตัวนั้น แต่คือไม่รู้เลยว่า bot ตัวอื่นมีปัญหาเดียวกันไหม
CTO มองอีกมุม – เริ่มสร้าง agent ที่สองตัว ตอนนี้สิบห้าตัว บางตัวผ่าน review บางตัวไม่ผ่าน ไม่มีใครรู้ว่าอะไร live อยู่บ้าง ใครเป็นเจ้าของ หรือ access data อะไรได้บ้าง
คนละ role แต่ root cause เดียวกันฮะ - บริษัทนี้ไม่ได้แค่เพิ่งเริ่มลองสร้าง GenAI application แล้ว แต่ต้อง operate GenAI at scale ซึ่งต้องการวิธีการจัดการคนละแบบกัน
มันเกิดขึ้นได้ยังไง
เมื่อเราเริ่มสร้าง GenAI application มากขึ้น มากขึ้น มันค่อยๆ drift ไปเองตามจำนวน agent ที่เพิ่มขึ้น และมักจะเป็น pattern เดิมทุกครั้ง
ช่วงแรก (1–5 agents) – manual coordination พอได้ ทีมเล็ก ยังจำภาพรวมได้ในหัว มีชุด convention เดียวเพราะมีแค่ทีมเดียวเขียน
กำลังโต (10–20 agents) – tool เดิมยังดี แต่ละทีมเริ่มใช้ต่างกัน tag ต่างกัน metadata ต่างกัน eval coverage ต่างกัน ไม่มีใคร agree standard เพราะยังไม่จำเป็น
ที่ scale (20+ agents) – ปัญหาเริ่มเกิด ไม่ใช่เพราะ tool แย่ลง แต่เพราะ operational complexity ไม่ได้โตเป็นเส้นตรงตามจำนวน agent – มัน compound ฮะ
ตัวเลข 5, 10, 20 เป็นแค่ illustration นะครับ จุดแตกหักจริงขึ้นอยู่กับทีม, regulatory exposure, และความ discipline ของ convention บางทีมเจอปัญหาที่สิบสอง บางทีมสบายถึงสี่สิบ
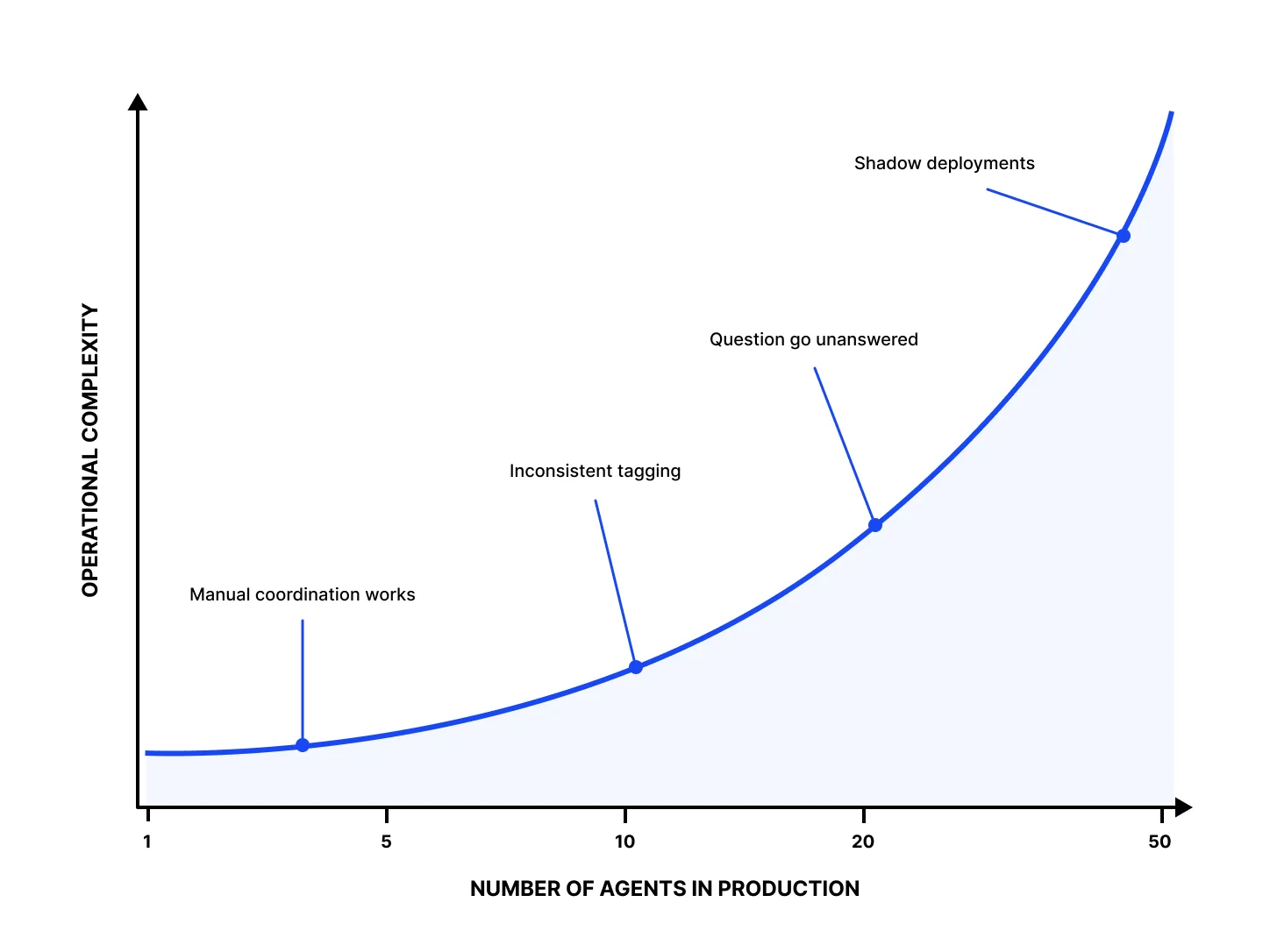
ปัญหาตรงนี้ไม่ใช่เรื่อง monitoring ครับ ส่วนใหญ่มี monitoring กันอยู่แล้ว ปัญหาคือ monitoring อยู่กระจัดกระจาย ไม่มี shared contract ที่ agent ทุกตัวต้อง build ต่อกัน ไม่มี central registry ไม่มี required metadata ที่ทำให้ finance ถามคำถามเดียวแล้วได้คำตอบเดียว
ผมขอเรียกช่องว่างนี้ว่า centralization gap และการจะปิดมันได้ต้องการอะไรที่ enforce standard จริงๆ ไม่ใช่ wiki ที่ทุกคน "ควร" ตาม – infrastructure ที่ทำหน้าที่นี้คือสิ่งที่เราเรียกว่า AI Governance Service
AI Governance Service คืออะไร
AI Governance Service คือ middleware ที่นั่งอยู่ระหว่าง AI request ทุกอันที่บริษัทส่งออกไป กับ AI provider ทุกเจ้าที่ใช้ ทุก prompt, ทุก response, เงินทุกบาทที่ใช้จ่าย ผ่านมันหมดฮะ
คิดง่ายๆ ก็คือ API gateway แต่สำหรับ GenAI
เหตุผลที่ต้องมี API gateway หน้า services ก็เหมือนกันเลย ไม่อยากให้แต่ละทีมมา rebuild rate limits, auth, และ logging เองทุกคน ก็เลยวาง layer เดียวไว้ข้างหน้า แล้วทุก service รับ controls นั้นมาอัตโนมัติ
logic เดิมครับ แค่ controls ต่างกัน – identity, budget, catalog approval, guardrails, cost attribution, PII scrubbing ทั้งหมดนี้ enforce ที่ platform ไม่ใช่ข้างใน agent แต่ละตัว
สองจุดตรวจ
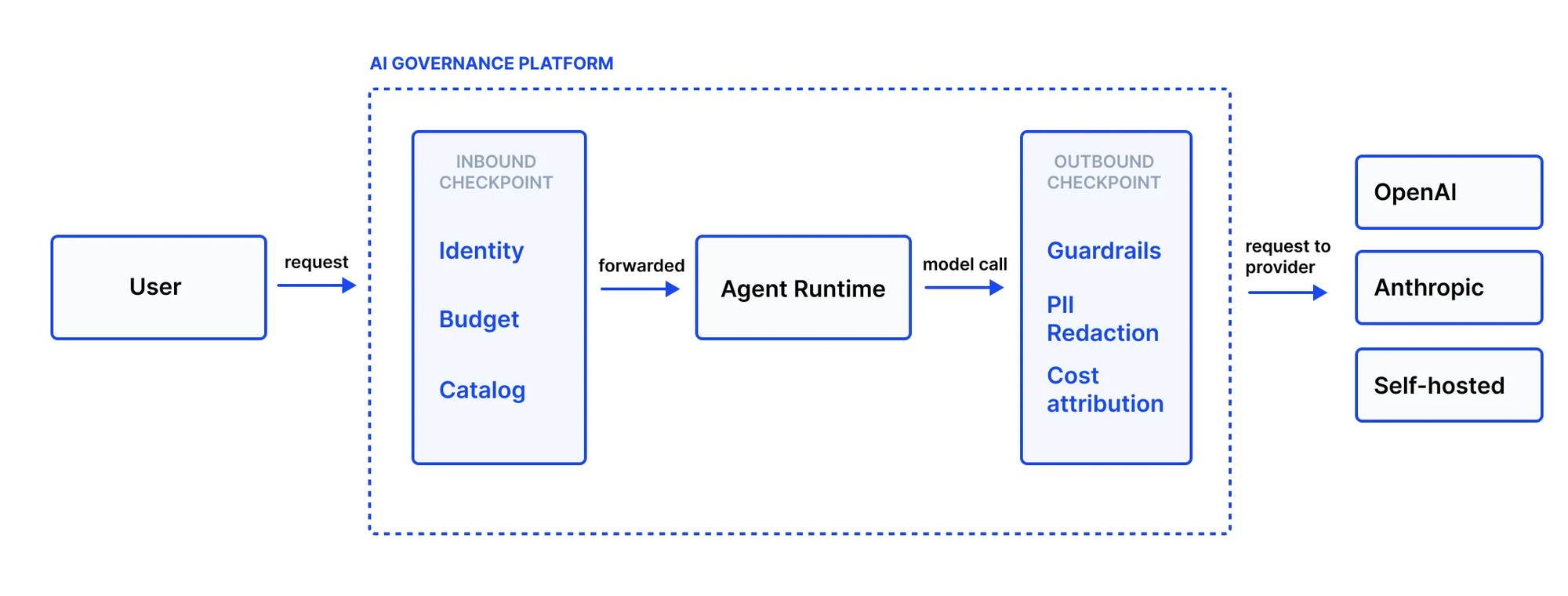
ทุก request ผ่านสองจุดฮะ
Inbound checkpoint
ก่อน request ไปถึง agent ใดๆ platform ถามสามอย่าง: User คนนี้คือใคร, User นี้ยังมี budget เหลืออยู่ไหม? agent ที่จะเรียก register และ approve แล้วหรือยัง?
ถ้า budget หมด request โดน reject ที่ gateway เลย ไม่มี agent code ที่ run, ไม่มี model ที่ call ออกไป, ไม่มี cost ที่เกิดขึ้น – บริษัทส่วนใหญ่รู้ว่า overspend ตอน invoice มาแล้ว Governance service หยุดมันตั้งแต่ตอนที่พยายามจะเรียกใช้
ส่วน agent catalog ก็จะ check ทุก agent ว่าต้องลงทะเบียนใน catalog ก่อนถึงจะถูกเรียกได้ ทุก change รวมถึง prompt change ต้องเข้า approval queue ก่อน reviewer เห็นว่าเปลี่ยนอะไร approve หรือ reject แล้ว version ใหม่ถึงจะใช้ได้ และนี่คือจุดที่จะหยุดปัญหาที่ว่า "แค่แก้ prompt นิดหน่อย" ไม่ให้กลายเป็น compliance gap แบบเงียบๆ
Outbound checkpoint
agent ทำงานเสร็จ จะ call model ก็ผ่านจุดตรวจที่สองก่อน นี่คือที่ที่ guardrails ทำงาน – PII filtering, prompt-injection defense, content policy
สิ่งที่สำคัญสุดคือ order of evaluation ครับ organization-level rules apply ก่อน แล้ว agent-level rules วางทับ ถ้า org block topic นั้นไว้ ไม่มี agent ไหน override ได้ org policy ชนะทุกครั้ง
ขากลับ cost ถูก attribute ที่ token level ไปยัง team, user, agent, และ model ที่ถูกต้อง ตอน finance ถามเรื่อง AI spend by business unit คำตอบก็สามารถดึงได้โดยง่ายฮะ
ตัวอย่างจริง
ลูกค้ารายนึงที่เราได้มีโอกาสทำงานด้วย ใช้ LibreChat เป็น internal AI interface มี dev จากหลาย business unit กำลัง build custom agents, มี usage จริงและกำลังโต
สิ่งที่ต้องทำงานได้ที่ infrastructure layer (ไม่ใช่ข้างใน agent แต่ละตัว) มีสี่อย่าง:
- Approval workflows – ทุก agent ใหม่หรือที่อัพเดทผ่าน review ก่อนถึงจะถูกเรียกได้
- Cost tracking – visibility ระดับ token พร้อม hard budget caps ที่ block requests ก่อน hit external provider
- Organization-level guardrails – apply สม่ำเสมอทุก interface และ agent, PII stripped ออกจาก compliance logs ก่อน store
- Red team evaluation – run ใน CI ทุก deployment, ผลติดตามเป็น trend ไม่ใช่เก็บครั้งเดียวเพื่อ audit
เราใช้ LiteLLM เป็น routing core ครับ handle multi-provider routing และ expose unified API ไม่ว่า backend จะเป็น GPT, Claude, หรือ self-hosted model governance logic วาง layer ทับบนนั้น
architecture แบ่งเป็นสาม zone:
- Governance & gateway – API routing, agent discovery, budget enforcement, guardrails
- Runtime – individual agents ที่รันใน Docker containers
- Evaluation – red team runner, prompt evaluation CI, agent catalog พร้อม approval queue
Cost ingestion ผ่าน Langfuse พร้อม full metadata ทุก request ซึ่งรวมถึง agent, user, model, token counts, tools called, และ total attributed cost FinOps dashboard แสดง spend สี่ระดับ: org-wide daily spend, per-agent cost, per-user consumption, และ per-model breakdown
ผลที่ได้ – finance ดึง cost by business unit ได้โดยไม่ต้องทำ spreadsheet, compliance มี guardrail coverage สม่ำเสมอทุก agent รวมถึงตัวที่ build หลัง platform ship ไปแล้ว, ทุก prompt/code change ผ่าน approver ก่อน, และ infrastructure แบก governance ไว้เอง agent แต่ละตัวไม่ต้องทำเองอีกต่อไป
ใครต้องการสิ่งนี้วันนี้
platform แบบนี้ไม่ใช่สำหรับทุกคนฮะ ต่ำกว่ายี่สิบ agent manual coordination ยังได้ถ้าทีม discipline พอ ข้ามยี่สิบไปแล้วมักจะเริ่มจัดการยาก
สัญญาณที่ชัดสุดว่าผ่านเส้นนั้นแล้ว คือตอน CFO ส่งข้อความถามว่าทำไม AI bill ถึงเพิ่มเป็นสองเท่า แล้ว engineering lead ตอบไม่ได้ภายในวัน
ถ้ายังไม่ถึงตรงนั้น ยังไม่ต้องสร้างครับ อยู่แบบ lean ต่อไป ship ของออกไปก่อน แล้วค่อยกลับมาดูใหม่ในอีก 2-3 เดือนข้างหน้า
Tools ในตลาด
ไม่จำเป็นต้อง build เองทั้งหมดนะครับ มีหลายตัวที่น่าดู:
| Tool | Type | เหมาะกับ |
|---|---|---|
| LiteLLM | Open source | อยากเอา gateway ขึ้นได้ในสัปดาห์เดียว – multi-provider routing ดี community ใหญ่ |
| Portkey | Open source / Commercial | ตัวนี้เด่นเรื่อง guardrails, มี sso, มี audit log, ui ดูดี |
| Bifrost | Open source | Claimed ว่าเรากว่า LiteLLM มาก ถ้าต้องการ support traffic, low latency ลองดํครับ |
| Helicone | Open source / Commercial | ตัวนี้เด่นเรื่อง Observability ครับ |
เราลองทุกตัวในการ deploy จริงครับ แต่ละตัวทำได้ส่วนหนึ่ง ไม่มีตัวไหนทำได้ครบแบบที่เราต้องการจริงๆ เลยต้อง build layer ของตัวเองทับขึ้นไป
สิ่งที่ขาดอยู่สองอย่างใหญ่คือ:
- Infrastructure cost tracking – ส่วนใหญ่ track AI cost ระดับ token ได้ แต่ไม่ track infrastructure cost ควบคู่กัน สำหรับ chargeback ไปยัง business unit ต้องการตัวเลขทั้งสองในบัญชีเดียวกัน
- Catalog with approval workflow – อยากให้ทุก asset ทั้ง agents, models, และ MCP tools ถูก review และ approve ก่อนถึง users เราอยากได้ code-review-style บน every change พร้อม audit trail ข้ามทุก version
สรุป
ปัญหาไม่ใช่การมียี่สิบ agent ฮะ
ปัญหาคือตอนที่ไม่มีใครตอบคำถามพื้นฐานได้ – agent ไหน live อยู่บ้าง, ใครเป็นเจ้าของ, access data อะไรได้, cost เท่าไหร่, เกิดอะไรขึ้นถ้ามันพัง
ที่ห้า agent, ยังสบาย ๆ พอสิบ รอยร้าวเริ่มเห็น พอยี่สิบ finance, security, และ leadership เริ่มถามคำถามที่ทีมตอบได้ไม่ทัน
คำถามที่ดีกว่าจะ build หรือ buy คือ อะไรต้องถูก centralize ก่อนที่ AI adoption จะโตเกินกว่าที่จะมองเห็นได้
ถ้าองค์กรกำลัง scale AI agents และต้องการ governance, cost visibility, หรือ production-ready infrastructure ที่ดีขึ้น มาพูดคุยกันได้ครับที่ info@arcfusion.ai ครับ 🙏